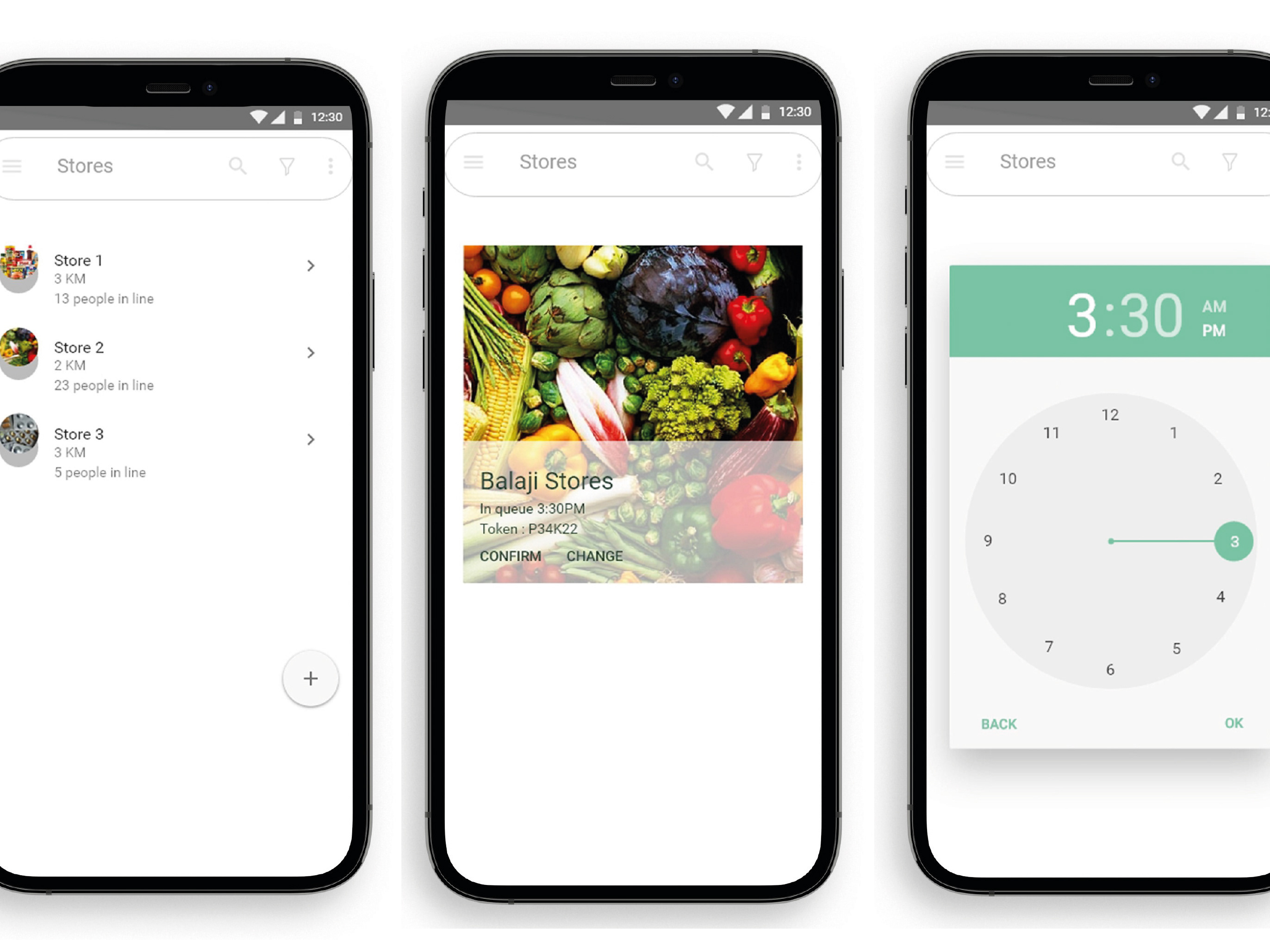
How Algorithms Run Amazon’s Warehouse
ABSTRACT :
Amazon — one of the largest E-commerce platforms was founded about 25 years ago. While this company would not function without its backbone, the labour force, the programmatically defined part of Amazon is also a major contribution — the part that we don’t see directly.
Following an item, from its being ordered to its being delivered is a very fast object localization. This poses clutter for robotic bin picking, which is an essential part of the working of this company. The Amazon Fulfilment Centre is where items from various sellers are stored, and dispatched after a user orders them. The Fulfilment Centre involves several processes — picking an item, sortation, packing and shipping. ‘Pickers’ who are assigned to pick items from various aisles, as they are ordered, have to work around 12 hours a day. Can the time is taken by a picker to do his/her task be optimized? This paper includes the analysis of the algorithm involved in picking an item, and an improvement to try and reduce the workload on the ‘pickers’.
CONCLUSION:
In conclusion, we chose to look at the pickers as humans and not as robots. As we found out that in Amazon’s algorithm, the workers were considered last, we decided to revolve our study around them. With them in the focus, we hope to optimize the process to reduce the efforts of the pickers and thus make the functioning of the warehouse more efficient.
1. Order Placement and location of the warehouse
This happens when the user places an order on the website. Once the order is placed, the warehouse where the item can be fetched is located. This depends on a number of factors.
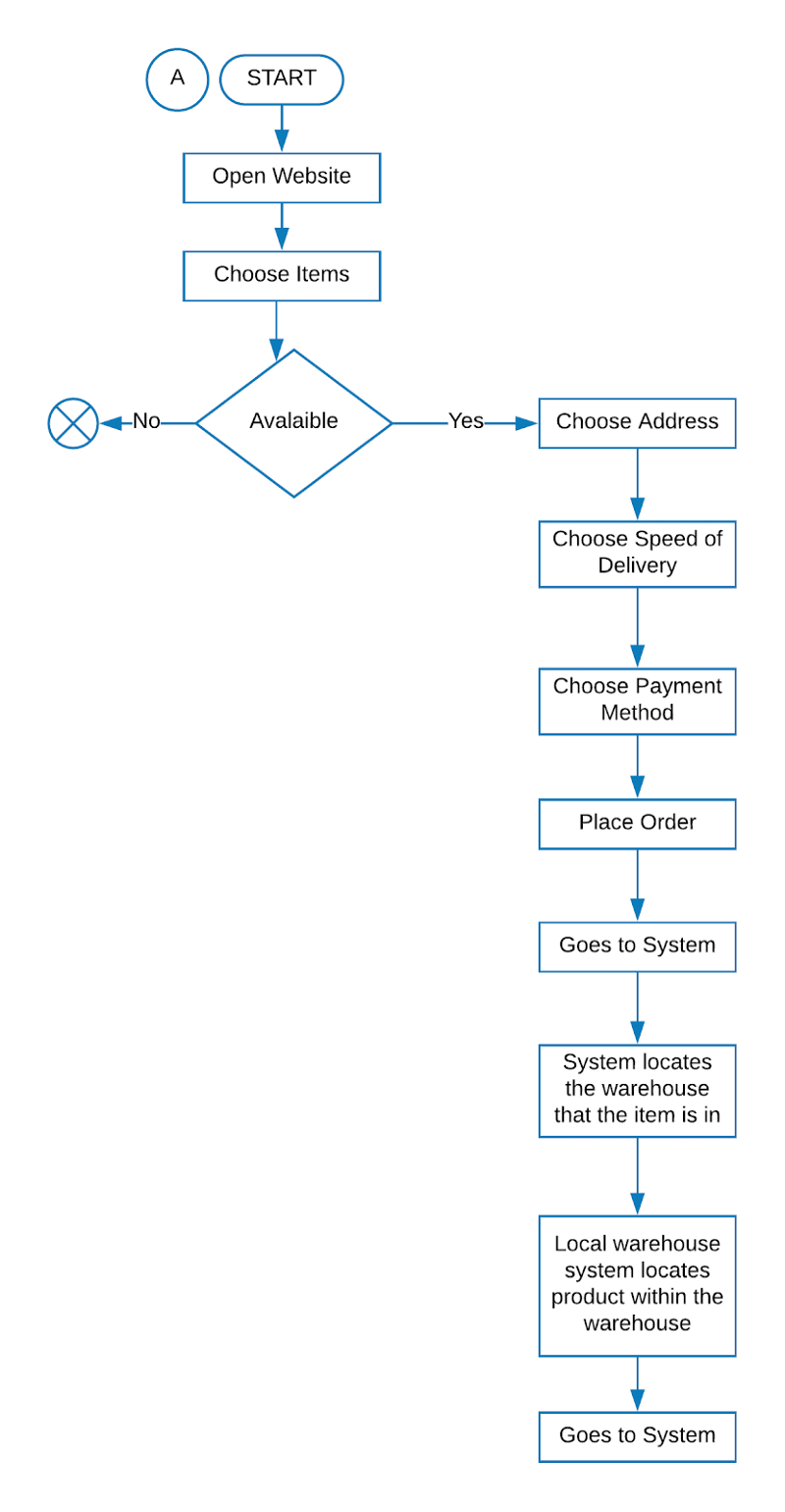
2. Building of inventory in the warehouse
Dealers book an appointment to stock their inventory in the AFC. All the items have barcodes generated by the Amazon dashboard. The receiving clerk measures weighs and scans the item. Then the items are moved to random storage, where they are just assigned a random location in the warehouse. While placing each item, the clerk scans it, so that the system would know its location.

3. Picking of items within the warehouse
A ‘picker’ is assigned to the item, who is supposed to locate the item from a given aisle and fetch it from there. He gets a list of aisles the items are to be picked from. Once the picker reaches a particular aisle, he scans the location, and the ‘handheld gun’ tells him/her what item to pick up from the aisle. He then picks up the item, scans it and adds it to his ‘tote’. He does so for multiple items until his tote is full and is ready for the next process.

4. Sorting of items from tote
Since the tote consists of items from various customers, the items are first separated into sorting trays. All the items are run through a sorter, where each sort tray is scanned by a laser. The items are re—binned according to the customer who has ordered them. Once all the items belonging to one customer have been collected, they move to the next process.
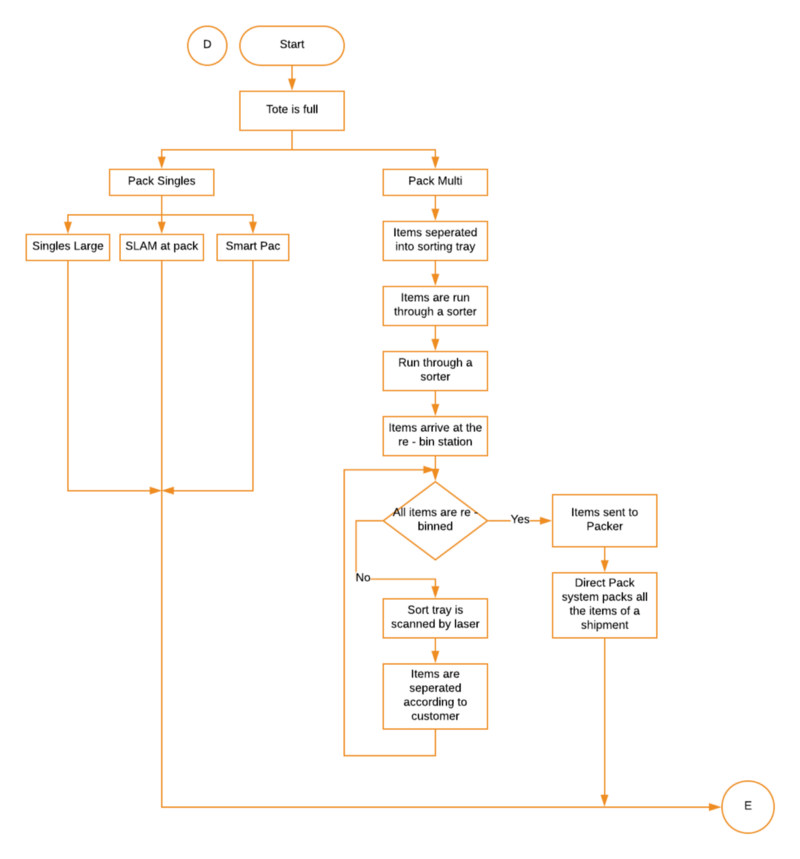
5. The Packer or Chuter and SLAM
The packer packs all the items belonging to one customer and attaches a sticker which is scanned with customer information (also called the SP00). Once the package goes to SLAM, it is weighed, and measured and a label is generated. The package then goes on to shipment.
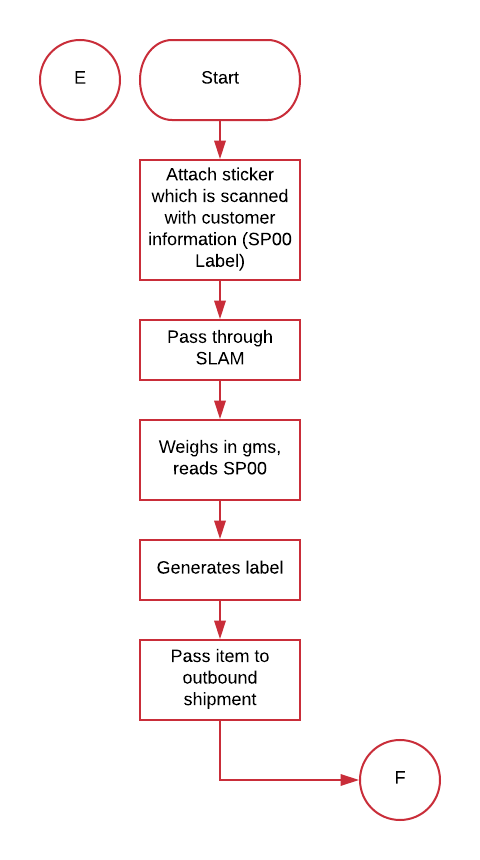
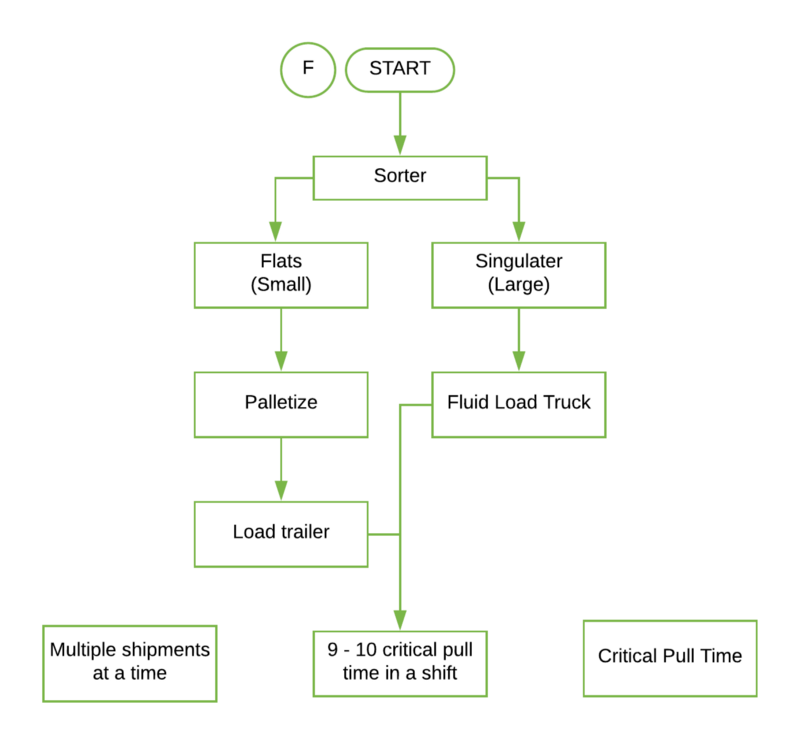
6. Shipment
Packages from different users are sorted into ‘flats’ or ‘singulators’ and then either loaded onto trailers or fluid loaded into trucks. Multiple shipments go out at once.
Step 3 of the above process is what we will be looking at in detail.
The sources we referred to gave us an idea about how warehouses function. The information was not specific to Amazon. This is a consolidated version of what we gathered.
Order picking optimization methods -
To further break down order picking, it can be carried out in various ways called Order Picking Systems (OPS). They can be designed keeping in mind the kind of products (size, number and value), customer orders and layout of the warehouse area. They are classified as the following :
1. Picker-to-parts
Pickers move between aisles and pick up items from them. They could either pick up items from a single order, or from multiple orders. This can be further divided into low level picker-to-parts where the items are available on the warehouse floor, and high level picker-to-parts where lifting trucks or cranes have to be used to pick up items.
2. Picker-to-box
Pickers are assigned zones that they have to move within to pick items. They are only assigned items that fall in their zone. Orders can be picked sequentially, zone wise or simultaneously from all zones.
The advantages to this system are that since pickers get assigned a smaller area, they find it easier to get used to it, and in the long run this reduces pick time.
3. Pick and sort
In this system, there is no need to pick all items in one tour. Items are placed individually on the conveyor belt, and then sent to a sorting area. Here, a mechanical sorter sorts the items into customer orders. However, adopting a mechanical sorter requires extra investment, so not all warehouses can afford this facility.
A typical picking tour consists of the following, in increasing order of time required–
Set-up time — Initial time involved in administrative tasks like forming of the order, and emptying of the tote on the conveyor.
Pick time — Time involved in picking the item from the aisle
Search time — Time spent looking for the product after arriving at the aisle.
Travel time — Time spent moving from one aisle to another, and between the aisles and the drop station.
There are a few policies that need to be considered while optimizing an order picking process –
1. Storage policy
There could be any of these three types of storage in a warehouse. Dedicated storage is where a storage location, or a number of adjacent storage locations in the warehouse are dedicated to a particular item. This on the downside decreases space utilization, because a particular location is always saved for a product, even if the product is currently not present in the warehouse. Random storage is where one type of items are spread all over the warehouse, so that the item closest to the picker can be picked. This has a high space utilization, but it possible only in computer guided warehouses. Closest open location storage is a variation of randomized storage, where the pickers themselves can choose the empty location.
According to [CITE] our research, Amazon Fulfilment Centres use random storage to store inventory. This decreases travel time to each item.
2. Order consolidation policies
The two types of order consolidation policies are single order picking, where one customer’s order turns into a pick list and order batching, where there are multiple orders in one pick list. However, this gives rise to the problem of batching orders such that items can be picked at the same time to reduce travel path.
3. Order routing policies –
Optimal routing policies are tough to craft in the real world because algorithmic generated pick paths may seem illogical to pickers, and they might not end up following the pick paths. Besides, aisle congestion is not accounted for in optimal conditions.
Routing strategies are of three types. Return strategy is where a picker enters an aisle if there is an item to pick from it. The picker enters from the front of the aisle and once he/she reaches the furthest item to be picked in that aisle, returns to the front of the aisle. S — shaped strategy is where a picker traverses the entire aisle alternating from the front end and the back end. Largest gap strategy is where the picker tries to maximize the length of the aisle that is not traversed. The picker only enters the aisle up to the distance of the furthest item, and then returns. If the item is closer to the back end of the aisle, the picker enters the aisle from that end.
Algorithms involved in order picking optimization–
In the context of order picking, there are two main processes that occur.
1. A picker walking from one aisle to another, to pick up items.
2. A picker walking to the location of a particular item in the aisle.
Keeping in mind these two processes, there are two main algorithms involved in order picking. Travelling Salesman problem is used to find the shortest path between all locations of an order, usually starting and ending at the same point (here, could be the depot). The Shortest Path problem is used to find the shortest path between two particular items, when they’re not joined by a single edge.
The following is an analysis of the Travelling Salesman Problem, along with enhancements that can make it more efficient for order path generation.
The Travelling Salesman problem is described as a problem to find the shortest route to traverse all the nodes of a graph, starting and ending at the same vertex.
There are two enhancements that could be done to this algorithm. First, are Enhancements –
1. Exhaustive search — This searches through all the permutations of tours, and each time that a shorter one is found, that becomes the shortest. This, however, increases time complexity because it has to go through all the possible paths.
2. Nearest neighbour — This simply starts at a random current node, and looks at the closest node to it, until all the nodes have been visited. This, however, has no guarantee that it will yield a result close to the optimal result, so it is not used extensively.
The following is an analysis of the Dijkstra’s algorithm, along with enhancements that can be done to it, in order to implement it for order picking.
Dijkstra’s algorithm finds the shortest path between two vertices of a weighted graph.
Enhancements –
1. Subgraph partitioning — When entire warehouse (graph) is subdivided into a part that actually has to be checked. For example, if there is no item to be picked from the north of the warehouse, the algorithm will not include that part of the warehouse at all while calculating the pick path. One disadvantage of the method is that there has to be an additional mechanism to calculate the subgraph, which might end up being more expensive.
2. Bidirectional searching — When start and end nodes are explicitly given, this method is used to map all paths from the starting node to the target node. The algorithm runs simultaneously from the start node and the target node, which reduces its run time, thus making it more efficient in terms of time.
Simulation to understand the working -
Our first level of simulation of the warehouse was very basic. The warehouse was a 3x3 warehouse, with 3 items being able to be stored in each compartment of the warehouse (amounting to a total of 27 items). There are 3 types of items — A, B and C. There are 5 A type items, 6 B type items, and 4 C type items. The algorithm randomly allots a location to these items, among the 27 available locations. The locations that don’t have an item assigned to them are assumed to be empty.
The algorithm generates an order containing 10 items (assuming the capacity of the tote to be 10). The warehouse contains one picker, whose initial position is [0,0]. He moves along the aisles, being able to move both horizontally, and vertically. The algorithm finds a list of available locations for each item of the order, and then finds the location closest to the picker’s current location. The distance travelled by the picker is calculated using Manhattan distance. This new location is added to the path.
To further detail out the simulation, we established our aim. To allow the warehouse to process more orders per unit time, we had to reduce the effort taken by the picker that we would consider to be measured in time and distance.
A list of attributes contributing to the picking of items was made, following which we made a list of assumptions. We took into consideration aisle width (assumed to be 8 units), number of aisles (assumed to be 100), time taken to search for an item in the compartment (different for different levels of the compartment) and time taken to pick an item based on the size of an item.
The second level of simulation included a warehouse that was 100x100 aisles, with each compartment being able to store 10 items. The warehouse contained a total of 74,954 items of types A to Z. These items were randomly allocated positions. Unlike the previous simulation, here the concept of time was introduced. The initial speed of the picker was assumed to be 1 unit/ unit time. The time taken to search for an item was also included. In each shelf, where there are 10 items present, it was assumed that the first three were kept on the lowermost level (taking 5 units of time to search for), the next three were kept in the middle level (taking 3 seconds to search for since the level is at eye level), and the last four were kept on the top most level (taking 10 seconds to search for). The time taken to pick an item, based on its size was also considered. For the sake of simplicity, it was assumed that items of type ‘A’ to ‘H’ were the smallest, so took 5 seconds to pick. Items of type ‘I’ to ‘P’ were medium sized, so took 10 seconds to search for, and items of type ‘Q’ to ‘Z’ were the largest, so took 12 seconds to pick.
As done previously, an order with 10 items was generated. For each item of the order, the closest available location was calculated, along with time taken to search for the item, as well as to pick it (according to rules mentioned above). The total time taken to complete the order was calculated.
To further imitate a real warehouse, the number of pickers simultaneously picking the orders had to be increased. This was done using threading in python.
The factor of fatigue was introduced, and for every three items that were picked, the speed of the picker would reduce by 0.5 times the speed.
3 Methodology
In this paper, we hoped to look deeper into the warehouses of Amazon and attempt to optimize the process of the pickers so as to reduce the human efforts. In order to satisfy the dissertation, we carried out secondary research by looking into different papers and videos. This gave us data on the general functioning of warehouses and the process a package goes through after an order is placed. We picked up the details relevant to our problem area — the pick path.
We started with watching videos on how Amazon warehouse works. This gave a peek inside the warehouse and thus we got a fair idea about how things work in and around the warehouses. We referred to different papers based on the logistics of the working of warehouses, these spoke about the analysis of the algorithm of the pick path in the warehouse and generating problems based on the pick path in terms of the algorithms. Primary research for this topic was restricted as no warehouses are accessible to the outer public, due to issues with privacy.
4 Findings
In working time, pickers have several subtasks. Time used by collectors for search and collection, is often considered to be constant. Assuming pickers moving at a constant speed, the target optimization becomes distance travelled by the picker to meet all the required orders. Tactic storing regulates the storage of received products to the storage location. Purpose storing maintains one or more neighbouring storage locations for storing one type of product. On the other hand randomly storing each type of product.
5 Insights -
Assumption — speed of the picker was taken to be 5 units/unit time, aisle width was taken to be 8 units horizontally. The other assumptions were are mentioned above.
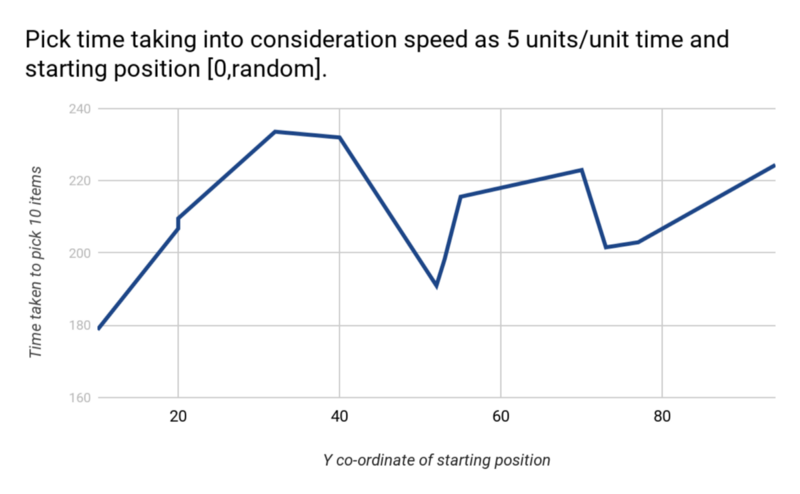
To find the total average total time taken by a picker to pick 10 items, two studies were conducted. One, taking the starting position of the picker as [0,0], the total time was measured. 12 observations were taken for this study. The average total time was 218.54 units.

Second, the starting position was decided randomly, assuming the picker started from the 0th row. The location was thus [0, (random value from 0 to 100)]. The average total time was 209.796 units.
Thus, it was inferred that no matter where (in the 0th row) the picker starts, he takes a similar amount of time to complete the order.
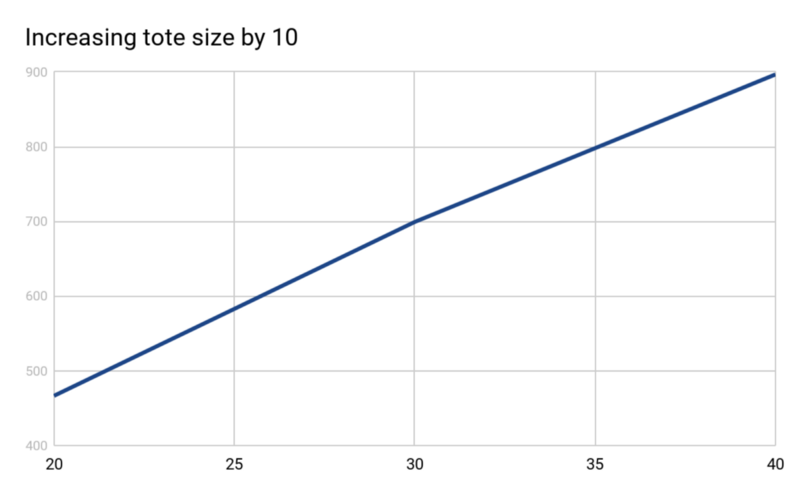
On increasing the tote size, it was found that time taken increases almost perfectly linearly with increase in tote size.
The project was done as a part of a college assignment with Manasi Kulkarni and Ananya Rane.